Sentimenti = Emotions. We’ve previously discussed how to accurately analyze emotions with automated tools. Today, we’ll explain how we gathered the data that led to the creation of Sentimenti tools. This article is a guide to conducting effective research on the emotional meaning of texts.
The text was prepared for the GHOST Day machine learning conference and you can view the presentation in Polish.
Sentimenti. What emotions?
To train machine learning algorithms to automatically identify emotions in text, we first had to ask people how they feel. This seemingly simple question had to be broken down into several components.
First, what types of emotions should we consider? How many are there, and how do they differ? To answer these questions, we consulted the emotion specialists from the LOBI team. In psychology, there are various models of emotions, from simple to complex and multidimensional. We ultimately chose two models, which we now refer to as the sentiment and emotion models.
The sentiment model, based on Russell and Mehrabian’s 1977 paper, describes emotions along two axes: positive-negative and high-low arousal. As for the emotion model, we adopted the Plutchik model, both for its scientific robustness and because a portion of the Polish Slavic network had already been classified using it. This alignment allowed us to compare our findings with expert annotations, serving as a key test for accuracy.
What words?
Once we knew how to classify emotions, the next question was: what words to analyze? Our first step was focusing on the emotional meaning of words. We compared our findings with databases like WordNet and NAWL.
Our goal was to create a list of 30,000 words or meanings. Some words are ambiguous, with emotional tones shifting depending on context. For instance, “depression” can refer to both terrain and a mood disorder. We limited ourselves to a maximum of three meanings per word, each presented in context.
Thanks to the WordNet project, we learned that 27% of words have emotional meanings. These emotionally charged words took precedence in our analysis.
Sentimenti project: who participated?
To analyze emotional undertones in texts, we needed insights from a representative group of speakers. We worked with the nationwide research panel Ariadna to gather participants. Over 20,000 people took part in the study, providing data on at least 50 words each.
How We Collected Emotional Data
We designed a tool to assess word meanings on scales reflecting both sentiment and basic emotions. Participants evaluated words based on the emotional overtones they perceived in given phrases.
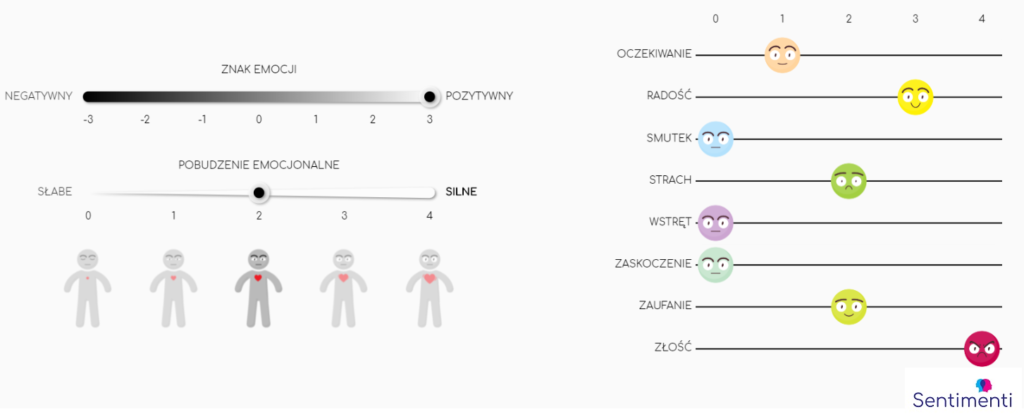
The study’s structure also considered participant fatigue. To ensure high-quality data, each person reviewed 150 words over three rounds, with breaks between rounds to maintain focus.
Beyond Words
Our next phase expanded beyond words to assess the emotional undertones of entire texts. Linguists have long known that the emotional meaning of a text goes beyond the sum of its words. The grammar and structure of a text also convey emotions.
For this phase, we analyzed existing reviews (e.g., hotels, doctors), as well as shorter forms like sentences and phrases. To ensure comparability with our word-level analysis, participants rated texts using the same emotional scales.
From People to AI
Sentimenti’s text classification tools now achieve high accuracy in identifying emotions, thanks to the solid dataset we built from word and text evaluations. While advanced neural networks may seem impressive, no AI can succeed without robust data to train on.
We’ve shared the details of our algorithm development both on our blog and in this scientific publication. Additionally, 20% of our word database will soon be published for researchers worldwide who study Polish emotions. This interactive database will have its own dedicated page, similar to NAWL’s list of affective words.