
by Agnieszka Czoska | Apr 9, 2020 | Sentimenti research
Dr Jan Kocoń is a natural language engineer and the person behind the machine learning process within SentiTool, our solution for analyzing emotions in the text. Dr Kocoń coordinates the work of the linguistics team, integrates individual elements of the tool, and works closely with the IT team.
If you have to describe Sentimenti and the tools to anybody, what would you say first?
Sentimenti is a project meant to analyze emotions hidden in the text. Unlike competitive solutions that recognize the overtones of the text only (positive, neutral or negative), our tools manage to understand the text, assign specific meanings to the words in the text and name the certain emotions people feel about them. These emotions, in turn, provide the knowledge base for a machine learning mechanism that automatically recognizes emotions at the level of sentences and the whole text.
What does it mean that we analyse emotions in the text?
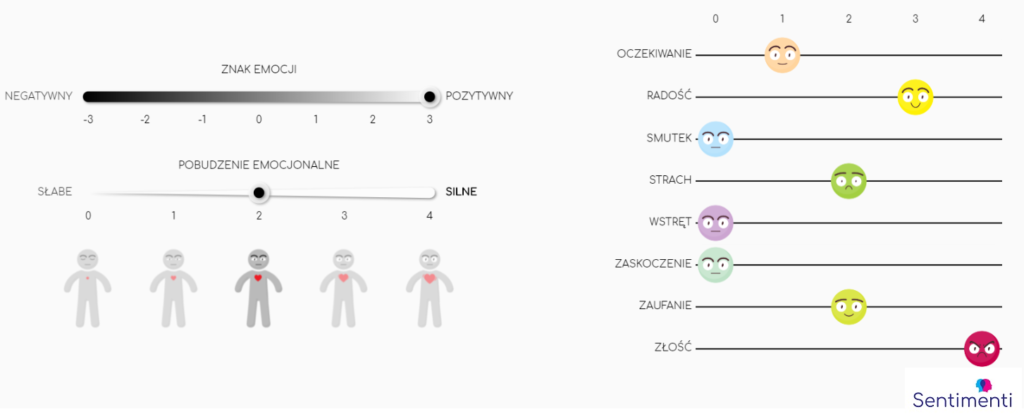
In the research carried out in our project we adapted the Plutchik model. It includes eight basic emotions: joy, sadness, trust, repulsion, expectation, fear, surprise and anger. We are able to estimate to what extent these emotions are expressed in the text.
How do we know what emotions people feel?
The knowledge base that helps our project includes more than 30.000 meanings of words, for which 20.000 unique respondents assign ratings for overtones and emotions. We are talking about “meanings” and not “words” on purpose, because words are ambiguous; for example “dark” means something different in “dark blue” or “dark people” and only in the latter case it carries emotions. Each meaning will ultimately receive 50 marks from different people. This allows us to know what feelings are evoked by certain meanings in the text. However, the emotion of the text is not a simple summation of the emotions assigned to the meanings in the text...
What else makes the emotion analysis tools in the text work?
Two things come to us to help. The first one is our gargantuan database of opinions. It came with associated overtones, derived from different areas: travel, medicine, products, services and more. We have over 10 millions of such texts in our database, which is an excellent source of information about the general feeling of the author. However, in order to find out what emotions a given text evokes in the reader, we also conduct our own research, analogous to research on single meanings.
This time the subject of these studies is the texts. The respondents attribute basic emotions to them, exactly the same way as they do with meanings of the words.
The second pillar of our Sentimenti tool is a combination of various machine learning methods. Experts in natural language processing provide us with tools for text analysis at the syntactic and semantic level, additionally they create rules for the analysis of meanings in context such as: negation, conjecture, weakening or strengthening of the overtones, etc. This is an additional help for automatic methods, such as deep neural networks, which are used to make the right conclusions about the emotions in the measured text.
What do you think automatic emotion analysis can be useful for?
Ultimately, I see many applications for our tools. The very first area that comes to my mind would be the marketing, or, more precisely, display advertising. This certain area covers the market of advertisements displayed in the context of web articles and is matching them with the emotions that the text of the publication evokes in readers. For example, in a sad text there could be an advertisement of an insurance company, and in a merry, joyful text there could be an advertisement for a trip.
Another area that we could cover is brand monitoring, i.e. analyzing how companies’ customers write on the Internet about a given company, its products and what emotions accompany them. Another interesting area could be sorting customers’ email complaints against the emotions contained in them, detecting conflicts arising in employee correspondence, detecting upcoming crises in Social Media, and even the possibility of diagnosing mental illnesses – the potential of Sentimenti tools is really huge!
What else do you plan to do in Sentimenti?
So far, there is a prototype ready with a simple text analysis on the level of meanings with an overtone analysis using our huge opinion resources. Currently in the Sentimenti team in Wroclaw I am managing to build a machine learning mechanism. It will make it possible to aggregate both information from the meaning knowledge base and information from the natural language processing stream. We are constantly receiving new data about the feelings of people reading certain texts, which are our teaching collection. The more data we gather, the better the quality of the tool there is.

by Agnieszka Czoska | Apr 9, 2020 | Sentimenti research
You’ve been in Sentimenti from the beginning. What was it like in 2016?
The business idea for the study of emotions in the text came from W3A.PL company from Poznan. After consultations with the environment of Poznań psychologists, cognitive scientists and linguists, a draft of the project for NCBiR (National Centre for Research and Development) was prepared and the search for subcontractors started. After estimating the market, it turned out that two units are capable of undertaking such advanced research work: LOBI IBD PAS and Language Technology Group of Wrocław University of Technology.
Once you got the grant, how did you start working?
As a research manager I was responsible for organizing the work of the team. It was important for me to combine the scientific teams of subcontractors and the business team into one team. The interface between business and science is not easy. In the Sentimenti team everyone – presidents, PhDs and MSc – speaks to each other by name, each person has the right to express their opinion and make decisions.
You are the research manager and scrum master of our team – how much did you have to learn to become one?
I learned the Scrum management methodology for R&D projects in the UK, where I worked in the Argument Analytics project conducted in cooperation with the University of Dundee and financed by Innovate UK, the British equivalent of NCBiR. I understood then that the key issue in the cooperation between science and business is good communication. A common team, preferably working in one place, frequent meetings and evaluation of results to check if this is really what we want – this is the heart of good projects. Many other R&D projects that I have observed did not achieve their goals precisely because of such a lack of communication.
How does the scrum method differ from your previous project experience?
I am a scientist and I have gained most of my experience in academic work and basic research. The transition to applied research was not easy, but I was given a lot by the British culture of openness, communication and respect – the values that are inscribed in Scrum and that we transfer to our team. The three pillars of Scrum are also important: transparency, inspection and adaptation. Transparency means that every person in the team – even new and unfamiliar with the subject – has access to all information (except, of course, confidential information). This helps a lot in overcoming crises, looking for a solution.
And what are inspection and adaptation?
An inspection is a frequent and short “review” meeting, during which we check what has already been completed, whether we do not have any obstacles that the project management should deal with, whether someone has too much or too little work. This helps to master the natural feature of research projects – unpredictability. When the results are different from we expected or when we get information from the business that a solution is not working – we can quickly adapt.
How do you see further development of Sentimenti?
In February, we have already finished our research work and moved on to development work, i.e. we use the collected knowledge and data in the work on Sentitol – our main tool for text analysis. Thanks to the fact that we use an iterative approach, we implement functionalities by adding them in subsequent versions of the product, and simultaneously – according to the Scrum methodology – we finish each Sprint (stage of work in Scrum) with a working product. At the moment, we have working software that recognizes eight emotions in texts in Polish, thanks to research on over 20 thousand people. This is already a solution that exceeds the scope of other solutions present on the market, and we are preparing two more versions.
In the next version of Sentimenti we will include a module using LSS (Lexical Syntactic Structures), i.e. elements of the language that affect the evaluation, e.g. good + no, + very, + a little. Then we will include a module that uses deep neural networks technology, or more precisely – BiLSTM (bidirectional long short-term memory neural networks), so that it can evaluate the emotions throughout the text immediately – and this is a unique solution on a Polish scale, but also worldwide. Our scientific publication about this module will be published soon.
Therefore, in the project we use fast prototyping, and in parallel to the work of the scientific team, the company implements any new solution for customers – because we have a great interest in our solutions. Thanks to this we have already achieved much better results (and faster) than we planned at the beginning.

by Agnieszka Czoska | Nov 8, 2019 | Conferences, Sentimenti research
Sentimenti = Emotions. We’ve previously discussed how to accurately analyze emotions with automated tools. Today, we’ll explain how we gathered the data that led to the creation of Sentimenti tools. This article is a guide to conducting effective research on the emotional meaning of texts.
The text was prepared for the GHOST Day machine learning conference and you can view the presentation in Polish.
Sentimenti. What emotions?
To train machine learning algorithms to automatically identify emotions in text, we first had to ask people how they feel. This seemingly simple question had to be broken down into several components.
First, what types of emotions should we consider? How many are there, and how do they differ? To answer these questions, we consulted the emotion specialists from the LOBI team. In psychology, there are various models of emotions, from simple to complex and multidimensional. We ultimately chose two models, which we now refer to as the sentiment and emotion models.
The sentiment model, based on Russell and Mehrabian’s 1977 paper, describes emotions along two axes: positive-negative and high-low arousal. As for the emotion model, we adopted the Plutchik model, both for its scientific robustness and because a portion of the Polish Slavic network had already been classified using it. This alignment allowed us to compare our findings with expert annotations, serving as a key test for accuracy.
What words?
Once we knew how to classify emotions, the next question was: what words to analyze? Our first step was focusing on the emotional meaning of words. We compared our findings with databases like WordNet and NAWL.
Our goal was to create a list of 30,000 words or meanings. Some words are ambiguous, with emotional tones shifting depending on context. For instance, “depression” can refer to both terrain and a mood disorder. We limited ourselves to a maximum of three meanings per word, each presented in context.
Thanks to the WordNet project, we learned that 27% of words have emotional meanings. These emotionally charged words took precedence in our analysis.
Sentimenti project: who participated?
To analyze emotional undertones in texts, we needed insights from a representative group of speakers. We worked with the nationwide research panel Ariadna to gather participants. Over 20,000 people took part in the study, providing data on at least 50 words each.
How We Collected Emotional Data
We designed a tool to assess word meanings on scales reflecting both sentiment and basic emotions. Participants evaluated words based on the emotional overtones they perceived in given phrases.
The study’s structure also considered participant fatigue. To ensure high-quality data, each person reviewed 150 words over three rounds, with breaks between rounds to maintain focus.
Beyond Words
Our next phase expanded beyond words to assess the emotional undertones of entire texts. Linguists have long known that the emotional meaning of a text goes beyond the sum of its words. The grammar and structure of a text also convey emotions.
For this phase, we analyzed existing reviews (e.g., hotels, doctors), as well as shorter forms like sentences and phrases. To ensure comparability with our word-level analysis, participants rated texts using the same emotional scales.
From People to AI
Sentimenti’s text classification tools now achieve high accuracy in identifying emotions, thanks to the solid dataset we built from word and text evaluations. While advanced neural networks may seem impressive, no AI can succeed without robust data to train on.
We’ve shared the details of our algorithm development both on our blog and in this scientific publication. Additionally, 20% of our word database will soon be published for researchers worldwide who study Polish emotions. This interactive database will have its own dedicated page, similar to NAWL’s list of affective words.

by Agnieszka Czoska | Mar 21, 2019 | Sentimenti research
The analysis of emotions in Sentimenti is based on the results of research on what emotions Polish language users associate with specific words, phrases and longer texts. Thanks to the results of subsequent research stages, our tool is still being improved. What research have we conducted so far?
Thousands of words and research participants
The most important part of the project is to collect evaluations of over 30 thousand words, phrases and texts from over 20 thousand Poles. Due to the scale of the project, we decided to carry out the research using two methods: CAPI (Computer Assisted Personal Interview) and CAWI (Computer Assisted Web Interview). Thanks to this, we were able to combine the benefits of both approaches: CAPI research allowed us to maintain strict control and high reliability of the research, while CAWI research allowed us to effectively reach such a large, representative group of Poles. Finally, with CAPI and CAWI data at our disposal, we can directly compare the assessments collected through both methods and check whether the research conducted online is as reliable as that conducted in a laboratory environment.
EmoTool – our research tool
In both studies we used our proprietary EmoTool application, through which the respondents indicated the emotions associated with particular words. The application includes 2 basic evaluation panels: the emotional dimension panel and the emotional category panel. Emotional dimension panel (left side) is used to determine the emotional overtones in the most general sense, i.e. to determine the direction and strength of emotions. The panel of categories of emotions (right side) allows to determine with which basic emotions a given word is associated to the respondents.

Combination of CAPI and CAWI methodology
What data did you collect? A total of 560 came to the laboratory, and more than 20 thousand unique respondents took part in the online research. CAPI participants evaluated nearly 3000 words, while CAWI participants evaluated over 30000 words (including all words from CAPI). Thanks to that, the biggest in Poland and one of the biggest in the world database of emotionally tagged words was created. Each of them has been evaluated at least 50 times, thanks to which we are able to estimate how particular words are perceived in the Polish population. At the same time, we are dealing with a representative group of Poles, which additionally increases the credibility of the results. The collected demographic data will enable the SentiTool tool to be tuned for more specific applications, profiled for selected demographic groups. In other words, we will be able to approximate not only the average reception of a given text, but also how it may vary depending on the age, beliefs or education of the recipient.
One of the most important conclusions from the research to date is that the results of CAWI and CAPI have proved surprisingly consistent. This means that both methods allow us to obtain qualitatively similar assessments. This is important information for us, because it turns out that by conducting research on such a large scale, we do not give up the high quality of the collected data. In other words, we have shown that emotions can be asked about on the Internet as effectively as in the laboratory. What is more, using this method, we can examine emotions related not only to the text but also to other material chosen by the Client, such as emojis, logos, graphics, recordings or video clips.
The most positive and negative words
Among the words considered by the respondents to be the most positive were:
beautiful, loving, sunny, cheerful, tender, gift, delight, joy, warmth and care.
In turn, the worst associations were found:
terrorist, beatings, war, paedophile, genocide, violence, aggression, pervert, murder and cheating.
These results are quite intuitive and thus confirm the reliability of the data collected by Sentimenti. The next comparison leads us to less obvious conclusions. Sometimes it seems to us that negative statements are more emotional, more striking, just stronger. Meanwhile, in the top ten, the words on the scale of strength are almost all positive:
to love pleasure, kiss, orgasm, mother, aggressive, in love, dinner, pass and euphoria..
The results of the research gathered so far through the EmoTool application are directly applicable to SentiTool, our automatic text analysis tool. Although the Sentimenti project can already boast several successes (for example, SentiStock analyses), we are still working on improving our tools. We have recently completed another stage of research, where participants evaluated not only words, but also phrases and whole texts. The data collected in this study will allow us to take a broader context into account in the process of text analysis and thus increase the effectiveness and accuracy of emotion detection.
The text was written together with PhD Monika Riegel and PhD Małgorzata Wierzba from LOBI.

by Agnieszka Czoska | Mar 14, 2019 | Sentimenti research
Each data analysis is aimed at understanding what information it contains. Has something changed, or is there a difference between A and B? Do changes in A correlate with those in C or D? Only these steps allow us to draw conclusions about the results.
First stage: measurement. What is the text?
The above statement also applies to the analysis of emotions or sentiment. Its first stage is the MEASUREMENT, checking how many and what kind of emotions we find in a given text or set of them. The result of a simple emotion measurement shows the intensity of each of Plutchik’s 8 basic emotions supplemented by positive and negative sentiment and arousal (overall emotional temperature of the text). Sometimes we can afford to interpret it already at this stage. We did it in one of our first entries, where we analyzed short ads (what is important, we have already managed to improve the way the results are presented). By analyzing the ads we wanted to show something characteristic for the whole type of texts: the most important emotions are joy and trust, only at the very beginning of the story about the product the creators allow themselves to remember the negative ones – to show the hardships of life before the era of the best shampoo or grease in the world.
The correct results of the Emotional Measurement are those that are consistent with people’s feelings, after all, each of us is an expert on feelings. Our tool owes its correctness to the participants of research on emotions in Polish, which we conducted according to the best scientific standards.

Measurement is only the first step towards understanding the message and the emotions it contains. When we deal with many similar texts or collections of texts, we have to do something else. We want to find out which shop has the best opinions? Which version of our marketing content expresses the most enthusiasm or best shows interest in the subject? Which of the texts in the “Beauty” section will delight, move or warn the reader? We are talking about COMPARISON.
The second stage: comparison. Does this text differ from the average?
Comparison is perhaps the most important stage in the analysis of emotions – thanks to it we not only find out what the text is like, but also how it compares with others. We can compare directly – as we did when writing about lipsticks and lipsticks. Then we were interested in which of the topics has an advantage in terms of positive emotions and whether this difference is statistically significant. However, comparing several or a dozen or so different cosmetic brands cannot be done in this way, it would not be the correct approach. That is why in the text about beauty companies we used a comparison to the average – we needed some kind of background measurement, so-called baseline. This approach will be useful, for example, when comparing shops and brands. We then answer the question which brand has better or worse results than most of the industry.
The most general type of baseline would be the sum of emotions that characterize not only the domain, portal or texts of a given author, but simply language. In linguistics, the so-called Polyanna effect is known, which is that there are more positive than negative expressions in every language. Not only in the dictionary, but also in what we say – this effect expresses quite a general tendency of our minds to spend time and energy rather on pleasant things. In our research we very often see this tendency – joys and trust are emotions that appear in the greatest intensity not only in advertising. The fact that language has its emotional mean all the more reason to draw conclusions only based on comparison and not on the measurement itself.
Third stage: trends. What do emotions do?
The analysis of emotions is also about tracking changes in time, i.e. monitoring emotions. We can check whether sadness or revulsion show a growing trend, i.e. there are more and more of them in statements on a given topic or in the opinions of customers. If we notice a trend, which is statistically significant, we can predict what will happen in the future and if by chance it does not mean an impending crisis (depending on the slope of the trend line).
At this stage it is also possible to go beyond the data from the Sentimenti tools. We started with something simple, accessible and yet untouched by others – we compared the emotional temperatures of mentions of listed companies with the prices of their shares, published publicly. Sentistock is great, it allows you to determine what the investor mood really is and how it translates into stock market fluctuations.
This part of the analysis of emotions depends entirely on who and for what purpose wanted to examine the overtones of the text, the notes, the conversation. We have also managed to show which emotions correlate positively with reactions on Facebook and Twitter – that is, how to write, so that the observers would like to like or comment on the post. However, we might as well ask how emotions correlate with remembering information from the text. Studies on the psychology of emotions, including those conducted by our colleagues from LOBI, indicate that the overtones of the text have an impact on what and how well we remember. Correlation between customer feedback and online store sales? Our tools are designed for this type of research.
Why so many stages?
Emotions were not created for themselves. This is our advisory mechanism: they tell us what action to take. Tversky and Kahneman did not receive the Nobel Prize for their research, but for showing that the consumer, including the stock market, is not rational. This statement tells us two things:
- emotions shape the market,
- we need good tools and methods to study this impact.
Trying to understand the emotions “on the eye” we won’t know more than the average customer wanting to buy a new computer, reading all the available reviews and then deciding on the brand for which he or she has (and had) the warmest feelings. Maintaining scientific standards, checking whether differences and trends are statistically significant and even better correlate with other, harder indicators is the best way to find out. After all, we live in the era of big data and data analysis.