
by Sentimenti Team | Aug 5, 2021 | Conferences, Market research, Scientific publications
Place of publication:
- Conference: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing
Title:
Personal Bias in Prediction of Emotions Elicited by Textual Opinions
Authors:
Jan Kocoń, Piotr Miłkowski, Damian Grimling, Marcin Gruza, Kamil Kanclerz, Przemysław Kazienko
Abstract:
Analysis of emotions elicited by opinions, comments, or articles commonly exploits annotated corpora, in which the labels assigned to documents average the views of all annotators, or represent a majority decision. The models trained on such data are effective at identifying the general views of the population. However, their usefulness for predicting the emotions evoked by the textual content in a particular individual is limited. In this paper, we present a study performed on a dataset containing 7,000 opinions, each annotated by about 50 people with two dimensions: valence, arousal, and with intensity of eight emotions from Plutchik’s model. Our study showed that individual responses often significantly differed from the mean. Therefore, we proposed a novel measure to estimate this effect – Personal Emotional Bias (PEB). We also developed a new BERT-based transformer architecture to predict emotions from an individual human perspective. We found PEB a major factor for improving the quality of personalized reasoning. Both the method and measure may boost the quality of content recommendation systems and personalized solutions that protect users from hate speech or unwanted content, which are highly subjective in nature.
Link: ResearchGate

by Sentimenti Team | Jul 22, 2021 | Scientific publications
Place of publication:
Behavior Research Methods
Title:
Emotion norms for 6000 Polish word meanings with a direct mapping to the Polish wordnet
Authors:
Jan Kocoń, Arkadiusz Janz, Piotr Miłkowski, Monika Riegel, Małgorzata Wierzba, Artur Marchewka, Agnieszka Czoska, Damian Grimling, Barbara Konat, Konrad Juszczyk, Katarzyna Klessa, Maciej Piasecki
Abstract:
Emotion lexicons are useful in research across various disciplines, but the availability of such resources remains limited for most languages. While existing emotion lexicons typically comprise words, it is a particular meaning of a word (rather than the word itself) that conveys emotion. To mitigate this issue, we present the Emotion Meanings dataset, a novel dataset of 6000 Polish word meanings. The word meanings are derived from the Polish wordnet (plWordNet), a large semantic network interlinking words by means of lexical and conceptual relations. The word meanings were manually rated for valence and arousal, along with a variety of basic emotion categories (anger, disgust, fear, sadness, anticipation, happiness, surprise, and trust). The annotations were found to be highly reliable, as demonstrated by the similarity between data collected in two independent samples: unsupervised ( n = 21,317) and supervised ( n = 561). Although we found the annotations to be relatively stable for female, male, younger, and older participants, we share both summary data and individual data to enable emotion research on different demographically specific subgroups. The word meanings are further accompanied by the relevant metadata, derived from open-source linguistic resources. Direct mapping to Princeton WordNet makes the dataset suitable for research on multiple languages. Altogether, this dataset provides a versatile resource that can be employed for emotion research in psychology, cognitive science, psycholinguistics, computational linguistics, and natural language processing.
Link: ResearchGate

by Agnieszka Czoska | Apr 9, 2020 | Sentimenti research
Dr Jan Kocoń is a natural language engineer and the person behind the machine learning process within SentiTool, our solution for analyzing emotions in the text. Dr Kocoń coordinates the work of the linguistics team, integrates individual elements of the tool, and works closely with the IT team.
If you have to describe Sentimenti and the tools to anybody, what would you say first?
Sentimenti is a project meant to analyze emotions hidden in the text. Unlike competitive solutions that recognize the overtones of the text only (positive, neutral or negative), our tools manage to understand the text, assign specific meanings to the words in the text and name the certain emotions people feel about them. These emotions, in turn, provide the knowledge base for a machine learning mechanism that automatically recognizes emotions at the level of sentences and the whole text.
What does it mean that we analyse emotions in the text?
In the research carried out in our project we adapted the Plutchik model. It includes eight basic emotions: joy, sadness, trust, repulsion, expectation, fear, surprise and anger. We are able to estimate to what extent these emotions are expressed in the text.
How do we know what emotions people feel?
The knowledge base that helps our project includes more than 30.000 meanings of words, for which 20.000 unique respondents assign ratings for overtones and emotions. We are talking about “meanings” and not “words” on purpose, because words are ambiguous; for example “dark” means something different in “dark blue” or “dark people” and only in the latter case it carries emotions. Each meaning will ultimately receive 50 marks from different people. This allows us to know what feelings are evoked by certain meanings in the text. However, the emotion of the text is not a simple summation of the emotions assigned to the meanings in the text...
What else makes the emotion analysis tools in the text work?
Two things come to us to help. The first one is our gargantuan database of opinions. It came with associated overtones, derived from different areas: travel, medicine, products, services and more. We have over 10 millions of such texts in our database, which is an excellent source of information about the general feeling of the author. However, in order to find out what emotions a given text evokes in the reader, we also conduct our own research, analogous to research on single meanings.
This time the subject of these studies is the texts. The respondents attribute basic emotions to them, exactly the same way as they do with meanings of the words.
The second pillar of our Sentimenti tool is a combination of various machine learning methods. Experts in natural language processing provide us with tools for text analysis at the syntactic and semantic level, additionally they create rules for the analysis of meanings in context such as: negation, conjecture, weakening or strengthening of the overtones, etc. This is an additional help for automatic methods, such as deep neural networks, which are used to make the right conclusions about the emotions in the measured text.
What do you think automatic emotion analysis can be useful for?
Ultimately, I see many applications for our tools. The very first area that comes to my mind would be the marketing, or, more precisely, display advertising. This certain area covers the market of advertisements displayed in the context of web articles and is matching them with the emotions that the text of the publication evokes in readers. For example, in a sad text there could be an advertisement of an insurance company, and in a merry, joyful text there could be an advertisement for a trip.
Another area that we could cover is brand monitoring, i.e. analyzing how companies’ customers write on the Internet about a given company, its products and what emotions accompany them. Another interesting area could be sorting customers’ email complaints against the emotions contained in them, detecting conflicts arising in employee correspondence, detecting upcoming crises in Social Media, and even the possibility of diagnosing mental illnesses – the potential of Sentimenti tools is really huge!
What else do you plan to do in Sentimenti?
So far, there is a prototype ready with a simple text analysis on the level of meanings with an overtone analysis using our huge opinion resources. Currently in the Sentimenti team in Wroclaw I am managing to build a machine learning mechanism. It will make it possible to aggregate both information from the meaning knowledge base and information from the natural language processing stream. We are constantly receiving new data about the feelings of people reading certain texts, which are our teaching collection. The more data we gather, the better the quality of the tool there is.

by Agnieszka Czoska | Nov 8, 2019 | Conferences, Sentimenti research
Sentimenti = Emotions. We’ve previously discussed how to accurately analyze emotions with automated tools. Today, we’ll explain how we gathered the data that led to the creation of Sentimenti tools. This article is a guide to conducting effective research on the emotional meaning of texts.
The text was prepared for the GHOST Day machine learning conference and you can view the presentation in Polish.
Sentimenti. What emotions?
To train machine learning algorithms to automatically identify emotions in text, we first had to ask people how they feel. This seemingly simple question had to be broken down into several components.
First, what types of emotions should we consider? How many are there, and how do they differ? To answer these questions, we consulted the emotion specialists from the LOBI team. In psychology, there are various models of emotions, from simple to complex and multidimensional. We ultimately chose two models, which we now refer to as the sentiment and emotion models.
The sentiment model, based on Russell and Mehrabian’s 1977 paper, describes emotions along two axes: positive-negative and high-low arousal. As for the emotion model, we adopted the Plutchik model, both for its scientific robustness and because a portion of the Polish Slavic network had already been classified using it. This alignment allowed us to compare our findings with expert annotations, serving as a key test for accuracy.
What words?
Once we knew how to classify emotions, the next question was: what words to analyze? Our first step was focusing on the emotional meaning of words. We compared our findings with databases like WordNet and NAWL.
Our goal was to create a list of 30,000 words or meanings. Some words are ambiguous, with emotional tones shifting depending on context. For instance, “depression” can refer to both terrain and a mood disorder. We limited ourselves to a maximum of three meanings per word, each presented in context.
Thanks to the WordNet project, we learned that 27% of words have emotional meanings. These emotionally charged words took precedence in our analysis.
Sentimenti project: who participated?
To analyze emotional undertones in texts, we needed insights from a representative group of speakers. We worked with the nationwide research panel Ariadna to gather participants. Over 20,000 people took part in the study, providing data on at least 50 words each.
How We Collected Emotional Data
We designed a tool to assess word meanings on scales reflecting both sentiment and basic emotions. Participants evaluated words based on the emotional overtones they perceived in given phrases.
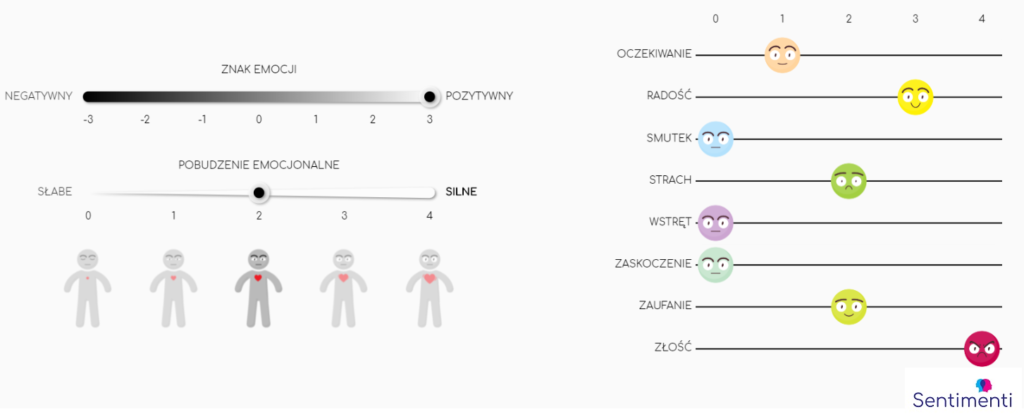
The study’s structure also considered participant fatigue. To ensure high-quality data, each person reviewed 150 words over three rounds, with breaks between rounds to maintain focus.
Beyond Words
Our next phase expanded beyond words to assess the emotional undertones of entire texts. Linguists have long known that the emotional meaning of a text goes beyond the sum of its words. The grammar and structure of a text also convey emotions.
For this phase, we analyzed existing reviews (e.g., hotels, doctors), as well as shorter forms like sentences and phrases. To ensure comparability with our word-level analysis, participants rated texts using the same emotional scales.
From People to AI
Sentimenti’s text classification tools now achieve high accuracy in identifying emotions, thanks to the solid dataset we built from word and text evaluations. While advanced neural networks may seem impressive, no AI can succeed without robust data to train on.
We’ve shared the details of our algorithm development both on our blog and in this scientific publication. Additionally, 20% of our word database will soon be published for researchers worldwide who study Polish emotions. This interactive database will have its own dedicated page, similar to NAWL’s list of affective words.