Ostatnimi czasy wielkim zainteresowaniem cieszy się tzw. generatywna sztuczna inteligencja (GenAI). Jest zdolna do generowania nowych danych, obrazów, tekstu lub innych treści na podstawie wzorców lub danych wejściowych, cytując ChataGPT. Albo inaczej, może tworzyć nowe dane, takie jak tekst, obrazy, filmy i muzykę. Opiera się na algorytmach uczenia maszynowego, które pozwalają jej analizować istniejące dane, a następnie generować nowe dane, które są podobne do danych oryginalnych, podążając za definicją Google Bard.
Te modele językowe traktowane są często przez użytkowników jak „wyrocznia znająca odpowiedzi na wszystkie pytania”. Twórcy tych rozwiązań pozwalają swoim narzędziom na opisywanie i recenzowanie nieomal wszystkich sfer naszego życia, w tym także emocji, jakie nam towarzyszą a użytkownicy z tego skrzętnie korzystają.
Czy jednak te opisy, odpowiedzi na pytania i recenzje są w pełni wiarygodne? I nie – uprzedając pytania – nie poruszamy w naszym badaniu wątku tzw. halucynacji AI… chociaż w swoich kłamstewkach potrafi być urocza, trzeba przyznać ;).

Pod koniec artykułu, dla wytrwałych, dzielimy się z Wami możliwymi negatywnymi konsekwencjami tego zjawiska.
Badanie sprawności działania generatywnej AI
Zespół naukowców wydziału inżynierii lingwistycznej Politechniki Wrocławskiej, w skład którego weszli też uczeni pracujący nad naszym rozwiązaniem „Sentimenti – analizator emocji w tekście” poddali badaniu porównawczemu ChatGPT i inne dostępne modele językowe (w tym także systemy do analizy sentymentu).
Jak wykazały badania wrocławskiego zespołu, GenAI najgorzej radziła sobie z zadaniami pragmatycznymi, wymagającymi wiedzy o świecie oraz właśnie z oceną emocji.
Nasze testy w Sentimenti
Pomiar sentymentu, emocji i pobudzenia emocjonalnego to kwintesencja Sentimenti. Dlatego też pokusiliśmy się o prosty test sprawdzający.
Cztery losowo wybrane teksty poddaliśmy analizie za pomocą „analizatora Sentimenti”; ChatGPT 4; ChatGPT 3.5 oraz GOOGLE BARD pod kątem zawartości emocji, jakimi emanują. Jako jednostkę miary jakości działania wskazanych programów przyjęto:
- MSE (mean squared error) – błąd średniokwadratowy jako współczynnik oceny błędu (który jest im mniejszy, tym korzystniejszy dla testowanego oprogramowania) oraz
- R² – współczynnik jakości dopasowania modelu (im jego wartość jest większa, tym lepsze jest dopasowane testowanego oprogramowania).
Punktem odniesienia dla sprawdzenia jakości działania wybranych programów były wyniki oceny emotywnej wybranych do analizy tekstów przeprowadzone na respondentach (ludziach) biorących udział w trakcie prac nad stworzeniem naszego analizatora emocji. Jako że wartości emocji prezentowane przez programy ChatGPT 4, ChatGPT 3.5 oraz Google Bard pokazywane są w dwóch miejscach po przecinku, dokonaliśmy analogicznych zaokrągleń w „analizatorze Sentimenti” i w rezultatach badania przeprowadzonego na respondentach.
Losowo wybrane teksty, poddane analizie GenAI
Tekst 1
Jako że wiele razy nocowałem w tym hotelu, moja recenzja niewiele się zmieni. Pod dosyć brzydką i zaniedbaną bryłą hotelu, kryje się ładnie wyremontowane wnętrze i sympatyczny personel. Pokoje są czyste, jasne i dosyć obszerne. śniadania wyśmienite. Niestety menu restauracji, jak we wszystkich Novotelach, jest fatalne, a potrawy skromne, niesmaczne i bardzo drogie. Na szczęście w Krakowie jest wiele miejsc, gdzie można dobrze zjeść. Zdecydowanie nie polecam restauracji, ale hotel jak najbardziej. Warto by pomyśleć o odnowie bryły hotelu, gdyż jest z innej epoki. Taka sama była w moich czasach studenckich, 25 lat temu!!!!
Tekst 2
Hotel w idealnym położeniu, jeżeli chodzi o łódź, dwie minuty od Piotrowskiej w samym centrum, ale jeżeli chodzi o czystość to tragedia łazienka śmierdziała a pościel brudna, na tą klasę hotelu to nie do przyjęcia
Tekst 3
Hotel tylko na jednodniowy nocleg w sprawach służbowych i nic poza tym. Po ostatnim kilkudniowym pobycie z rodziną zadecydowaliśmy, że będzie to nasza ostatnia wizyta w tym hotelu. Jedzenie standardowe dla wszystkich Ibisów, pokoje również. Obsługa na recepcji – ruletka. Po zameldowaniu dostaliśmy chyba najmniejszy narożny pokój w całym hotelu mimo wcześniejszej telefonicznej rezerwacji konkretnych pokoi na konkretnych piętrach, ponoć ze względu na obłożenie. Dziwnym trafem kilka minut później podczas obsługi przez innego recepcjonistę nasze pokoje się znalazły”. W pokojach niezbyt czysto, housekeeping nie zwraca uwagi na stawiane rodzaje wód mimo licznych próśb. Restauracja pozostawia wiele do życzenia.”
Tekst 4
Hotel położony niedaleko centrum Wrocławia. Pokój i łazienka czyste, kosmetyki ok, może trochę łóżko za miękkie, ale nie było źle. Śniadania całkiem dobre. Parking dodatkowo płatny 25 zł. Na bardzo duży plus chciałem ocenić obsługę. W recepcji wszystko sprawnie i z uśmiechem. Natomiast podczas śniadania jedna z pań kelnerek bardzo pozytywnie mnie zaskoczyła. Bardzo szybko zorganizowała stolik dla 8 osób, od razu doniosła krzesełko do karmienia dla dziecka, pytała dzieci jak się Wrocław podoba itd. W pewnym momencie moja 7 letnia córka zapytała, czy jest ketchup na co pani z uśmiechem: pewnie, że jest, już idę ci przynieść. Parę słów i gestów a robi wrażenie.
Wyniki
Przeprowadzony prosty test potwierdził wnioski wrocławskich naukowców, że w przypadku analizy emocji, chatboty znacznie ustępują specjalistycznym programom takim jak np. „Sentimenti”.


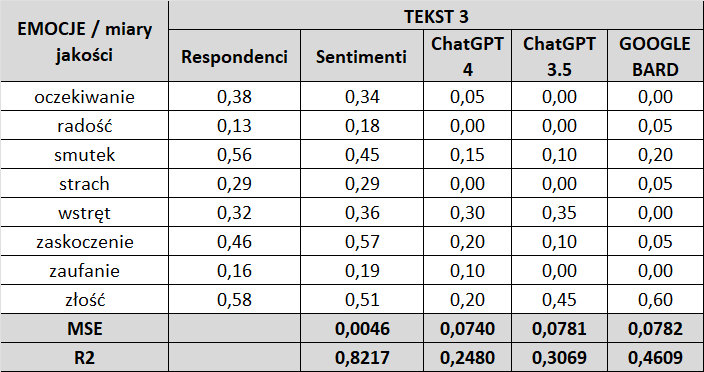
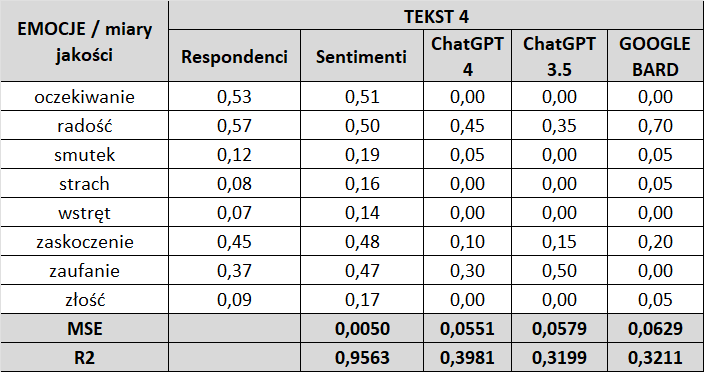
Punktem wyjścia są wyniki na osobach (Respondenci) i do nich przyrównujemy pozostałe modele: Sentimenti, ChatGPT 4.0, ChatGPT 3.5 i Google Bard.
Jak widać w przypadku analizatora Sentimenti, wartości wskaźników MSE i R² są zdecydowanie lepsze, niż w przypadku pozostałych programów.
Wskaźnik MSE – w przypadku „analizatora Sentimenti” jego wartość mierzona jest w trzecim, a nawet w czwartym miejscu po przecinku co pokazuje zbliżanie się błędu (w działaniu analizatora) do zera. Inaczej jest w pozostałych programach, gdzie wartość tego wskaźnika mierzona jest w drugim, a nawet w pierwszym miejscu po przecinku pokazując duży obszar błędu w działaniach tych programów.
Wskaźnik R² – w przypadku „analizatora Sentimenti” wartości tego wskaźnika mieszczą się w przedziale od 0,8217 do 0,9563, gdzie przedział 0,8 – 0,9 określany jest jako dopasowanie dobre, a przedział 0,9 – 1,0 jako dopasowanie bardzo dobre.
W przypadku pozostałych programów najwyższe miary wskaźnika R² dla:
- ChatGPT 4.0 – 0,3981
- ChatGPT 3.5 – 0,3769
- GOOGLE BARD – 0,4609
oznaczają dopasowanie niezadowalające.
Halucynacje GenAI
W przypadku generatywnych modeli pojawia się jeszcze jeden problem, na który zwracają uwagę wnikliwi analitycy. Jest to tendencja do wyrzucania przez program błędnych informacji.
Jeśli to zjawisko, określane jako „halucynacje”, byłoby zjawiskiem powtarzalnym, to istnieje zagrożenie, że ChatGPT przy kolejnym zapytaniu o poziom sentymentu dla jakiegoś waloru finansowego mógłby udzielić zupełnie innej odpowiedzi niż udzieliłby jej pierwotnie. W takim przypadku strategie inwestycyjne przyjęte przez inwestorów zostałyby zasilone błędnymi danymi mogącymi wpłynąć na wyniki transakcji finansowych.
Takiego niebezpieczeństwa nie ma w przypadku „analizatora Sentimenti”. Tutaj niezależnie od ilości zapytań o poziom emocji w konkretnym (tym samym) tekście za każdym razem otrzymujemy identyczne wyniki.
GenAI vs Sentimenti na rynkach finansowych
W ramach projektu Sentistocks, wykorzystujemy pomiar natężenia emocji do predykcji przyszłych wartości wybranych instrumentów finansowych. Pomiar natężenia emocji pozwala nam określić, w jakim kierunku zmierza nastrój rynku, zwany powszechnie sentymentem inwestorskim.
Korelacja natężenia tego wskaźnika (budowanego przecież na bazie emocji, jakie odczuwają inwestorzy) z danymi finansowymi pozwala przy wykorzystaniu wyuczonych modeli predykować przyszłe wartości instrumentów finansowych. Aktualnie model analizuje nastroje na rynku kryptowalutowym (predykcja kursu Bitcoina w przedziałach czasowych 15-minutowych).
Pojawiają się także informacje o wykorzystywaniu ChatGPT do przewidywaniu zwrotów z rynku akcji przy użyciu analizy nastrojów nagłówków wiadomości.
Jak wskazują autorzy przywołanej publikacji:
…analiza pokazuje, że wyniki sentymentu ChatGPT wykazują statystycznie istotną moc predykcyjną na dzienne zwroty z rynku akcji. Wykorzystując dane z nagłówków wiadomości i wygenerowanie sentymentu, znajdujemy silną korelację pomiędzy oceną ChatGPT, a późniejszymi dziennymi zwrotami akcji w naszej próbie.
Na uwagę zasługuje zwrot w publikacji:
wyniki sentymentu ChatGPT wykazują statystycznie istotną moc predykcyjną.
Nasz krótki test dla ChatGPT (4.0 i 3.5) pokazał, że mierniki jakości (MSE i R²) dla tych programów wykorzystywanych do pomiaru emocji stanowiących o sentymencie i jego kierunku są niezadowalające. A mimo to autorzy przywołanej publikacji uzyskali pozytywne wyniki swoich badań.
Można zadać w takim razie pytanie, o ile lepsze byłyby wyniki, gdyby do pomiaru sentymentu inwestorskiego wykorzystano nasz analizator Sentimenti, gdzie zwłaszcza wskaźnik R² był dla naszego rozwiązania ponad dwukrotnie wyższy niż zanotowaliśmy to dla ChatGPT?
Podsumowanie
Starając się być obiektywnym w naszym uproszczonym porównaniu, niestety widzimy szereg zagrożeń czy wręcz wykluczeń dla używania generatywnych modeli sztucznej inteligencji w profesjonalnych zastosowaniach, szczególnie w obszarach bazujących na pomiarze sentymentu i emocji. W naszej ocenie wynika to zarówno z konstrukcji samego rozwiązania, danych źródłowych dostarczanych do uczenia modeli, jak i samej koncepcji pomiaru sentymentu i emocji.
W szczególności:
- różnice w budowie modeli językowych: model Sentimenti budowany był od podstaw na bazie danych uzyskanych w wyniku być może największych na świecie tego typu badań, z udziałem ludzi. Tak przygotowane i ukierunkowane badania zazwyczaj skutkują z zawężoną funkcjonalnością jednak przy jednocześnie zdecydowanie wyższej jakości wyników w porównaniu z podejściem pozyskiwania danych de facto z każdego możliwego obszaru celem zapewnienia modelowi jak największej „wiedzy”.
- różnice w sposobie interpretacji sentymentu i emocji: w ramach projektu Sentimenti, badane osoby udzielały odpowiedzi na pytanie, jakie emocje okazany im tekst w nich wzbudza – minimum 50 różnych osób dla każdego z tekstów. Tym samym mierzony był odbiór tekstu przez czytelnika (odbiorcę wiadomości). W przypadku generatywnych modeli AI, dostajemy “subiektywną” ocenę danego modelu językowego. Tym samym jest ona bliższa próbie zgadnięcia intencji wywołania określonych emocji przez autora komunikatu (nadawcę wiadomości), a nie tego, jak ten komunikat może być odebrany. Taka interpretacja nie nadaje się w naszej ocenie do obiektywnego określenia emocji i zastosowania w narzędziach wykorzystujących pomiar sentymentu i emocji.
- halucynacje: ogólnie znany problem generatywnych modeli. W odróżnieniu od modelu Sentimenti, skupionego na ocenie 11 wskaźników emotywnych, gdzie taki problem nie występuje i ocena danego tekstu zawsze będzie dawała taki sam wynik, GenAI potrafi relatywnie często podać odpowiedź niezgodną z prawdą. W naszej ocenie wyklucza to używanie GenAI do profesjonalnych zastosowań językowych.