Sentimenti. Z dobrych badań biorą się dobre narzędzia do analizy emocji
Sentimenti to emocje. Pisaliśmy już o tym, jak poprawnie analizować emocje, gdy mamy sposób na ich automatyczny pomiar lub klasyfikację wzmianek. Dzisiaj opowiemy w jaki sposób zbieraliśmy dane pozwalające nam na stworzenie narzędzi Sentimenti. Czyli po raz kolejny piszemy jak dobrze coś zrobić – przeprowadzić badania nad emotywnym znaczeniem tekstów.
Tekst został napisany przy okazji wystąpienia na konferencji o uczeniu maszynowym GHOST Day. Tu można przejrzeć pokazywaną tam prezentację.
Sentimenti. Jakie emocje?
Żeby w ramach projektu Sentimenti wytrenować algorytmy uczenia maszynowego i automatycznie wskazywać emocje wyrażane w tekście, musieliśmy najpierw zapytać ludzi, jakie emocje czują. Tak proste pytanie musiało zostać rozłożone na kilka komponentów.
Po pierwsze – jakie emocje? Skąd mamy wiedzieć, ile ich jest, czym się różnią, jaka liczba kategorii będzie optymalna? Zajęli się tym specjaliści od emocji, ludzie z zespołu LOBI. W psychologii funkcjonuje kilka modeli emocji, od bardzo prostych po skomplikowane i wielowymiarowe. Zdecydowaliśmy się na dwa, które obecnie nazywamy po prostu modelami sentymentu i emocji.
Według modelu sentymentu zaproponowanego w artykule z 1977 roku przez Russella i Mehrabiana każdą emocję da się opisać na dwóch osiach: pozytywna-negatywna oraz wysokie-niskie pobudzenie. Jeśli chodzi o model emocji, jak wielokrotnie pisaliśmy, wygrał ten Plutchika. Oprócz względów naukowych przemawiały za nim praktyczne – część polskiej Słowosieci już została opisana emotywnie właśnie według niego. Dzięki zastosowaniu tego samego modelu (w poprawionym tłumaczeniu, nad którym też musieliśmy popracować) mogliśmy porównać wyniki naszych badań z eksperckimi anotacjami dostępnymi w tym zasobie. To jeden z naszych testów trafności wyników.
Jakie słowa?
Wiemy, jak anotować, ale co właściwie? Nasze pierwsze badanie miało skupić się na emotywnym znaczeniu słów. Zdecydowaliśmy, że w ramach testowania trafności wyników porównamy nasze z pochodzącymi ze Słowosieci, a dodatkowo bazą słów emotywnych NAWL (stworzoną dawniej przez naszych współpracowników z LOBI). Wobec tego jakaś część wyrazów musi pokrywać się z tymi zasobami.
Dążyliśmy do tworzenia listy 30 tys. słów lub znaczeń – w końcu mamy wiele wyrazów wieloznacznych, których wydźwięk emocjonalny także zmienia się w zależności od kontekstu. Na przykład depresja czyli obniżenie terenu to zupełnie coś innego niż zaburzenia nastroju. Uznaliśmy, że możemy wpisać na listę maksymalnie 3 znaczenia jednego słowa, a żeby wskazać uczestnikom badania, o które z nich chodzi, pokażemy każde w krótkiej frazie: depresja terenu, leczenie depresji.
Dzięki projektowi anotacji Słowosieci (przy jej rozwijaniu także pracują “nasi” ludzie) wiedzieliśmy, że około 27% słów języka polskiego niesie jakieś znaczenie emocjonalne. Z naszego punktu widzenia są one bardziej interesujące niż neutralne, więc miały pierwszeństwo. Poza tym kontrolowaliśmy naszą listę słów pod względem frekwencji słów (żeby mieć więcej tych częstych, ale także odpowiedni procent rzadkich).
Co z uczestnikami badania?
Jako zespół Sentimenti chcieliśmy móc powiedzieć coś o wydźwięku tekstów napisanych po polsku. Żeby naprawdę tak było, musieliśmy dowiedzieć się, jak rozumie je przeciętny, typowy użytkownik tego języka. Zgodnie z regułami naukowej sztuki musieliśmy przebadać reprezentatywna grupę Polaków – taką, której struktura odpowiada strukturze populacji pod względem wieku, wykształcenia i innych istotnych cech.
Takiego badania nie da się zrobić po prostu przez internet, w mediach społecznościowych, łapiąc ludzi na ulicy. Potrzebowaliśmy profesjonalistów, więc skorzystaliśmy z usług ogólnopolskiego panelu badawczego. Nasze zapytanie ofertowe wygrała Ariadna. Ta firma znalazła dla nas uczestników badania, ale my także kontrolowaliśmy przebieg badania. Musieliśmy zapewnić odpowiednią liczbę ocen wydźwięku każdego słowa (minimum 50 osób), nadawać uczestnikom badania identyfikatory (żeby móc zestawić ich odpowiedzi z danymi na temat wieku, miejsca zamieszkania i innych). W badaniu wzięło udział 20 tys. osób.
Jak pytać o wydźwięk słów?
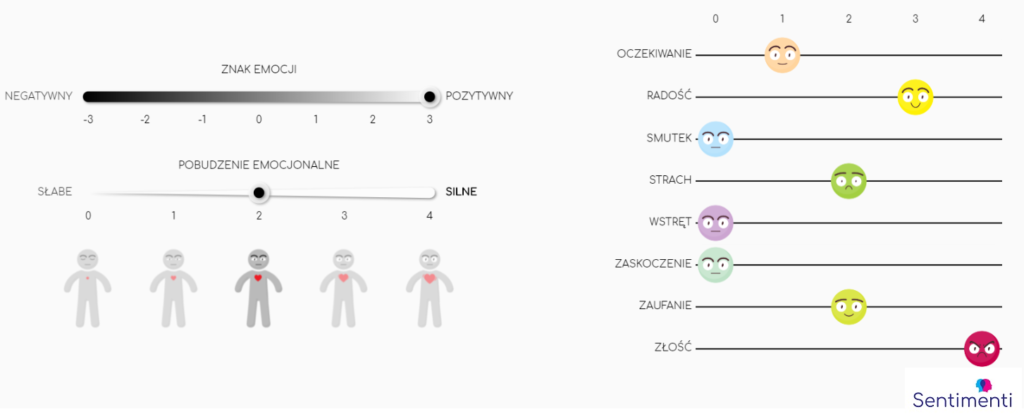
Sentyment i pobudzenie emocjonalne zwykle opisuje się na skali. Z kolei modele emocji są raczej kategorialne – pytają, czy emocja jest, czy jej nie ma. Chyba, że mówimy o modelu Plutchika, który od razu zakłada, że natężenie emocji może się zmieniać: na przykład od irytacji przez złość po wściekłość. W naszym modelu chcieliśmy jeszcze dodać punkt zero, brak jakiejkolwiek emocji ze spektrum złości.
Po wielu analizach i pilotach stworzyliśmy autorskie narzędzie do anotacji emocji, dzięki któremu każde znaczenie słowa wpisanego we frazę można było ocenić na skalach będących operacjonalizacjami modeli sentymentu i emocji podstawowych. Uczestnicy badania wskazywali wydźwięk słowa dzięki interfejsowi pokazanemu poniżej. Wcześniej otrzymywali także dokładną, prosto napisaną instrukcję, do której mogli wrócić w każdym momencie badania.
Bardzo ważnym etapem konstruowania badania było ustalenie, ile słów ma zobaczyć każdy uczestnik. Nie mogliśmy zajmować im zbyt dużo czasu chociażby dlatego, że zmęczeniu ludzie mniej uważnie czytają tekst i udzielają niestarannych odpowiedzi. Idealnym układem okazało się 150 słów (fraz) w trzech turach. Przerwy między turami mogły trwać nawet kilka dni. Dla nas liczył się czas spędzany nad każdą frazą (zbyt krótkie i zbyt długie musiały zostać odrzucone z wyników).
Dalej niż słowa
Nasze kolejne badanie miało dotyczyć wydźwięku tekstów. Językoznawcy nie od dzisiaj wiedzą, że od znaczenia słowa do znaczenia całego tekstu wiedzie kręta droga. Gramatyka i układ tekstu także wyrażają emocje.
Projekt zakładał, że przebadamy opinie – na przykład o hotelach i lekarzach. Zebranie opinii nie było trudne. Dodatkowo można było je podzielić na pozytywne i negatywne już na podstawie towarzyszących im gwiazdek lub ocen punktowych. Wyzwaniem było dobranie odpowiednich dziedzinowo tekstów neutralnych. Nasz korpus wzbogaciliśmy z krótsze formy, zdania i frazy, pochodzące między innymi z korpusu Paralingua lub naszych badań pilotażowych. Nieco później nasi koledzy pracujący także w zespole Słowosieci stworzyli korpus opinii (anotowany emotywnie już nie przez uczestników badań, tylko językoznawców).
Żeby wyniki były porównywalne z tymi dotyczącymi słów, przebadaliśmy wydźwięk tekstów z udziałem reprezentatywnej grupy osób na tych samych skalach, co słowa. To badanie objęło 2 tys. osób i 7 tys. tekstów i fraz. Każdy uczestnik przeczytał 50 tekstów, a każdy tekst oceniło co najmniej 25 osób.
Sentimenti to najpierw ludzie, potem AI
Obecnie nasze narzędzia do klasyfikacji tekstów pod względem emocji i sentymentu osiągają wysoką trafność dla każdej emocji. Najnowocześniejsze, najbardziej wymyślne sieci neuronowe czy inne algorytmy nie są w stanie tego dokonać bez dobrych danych. Mogliśmy nauczyć naszą sztuczną inteligencję emocji tylko dzięki temu, że zgromadziliśmy dobrze skonstruowaną bazę słów emotywnych i tekstów ocenionych przez reprezentatywną grupę użytkowników języka polskiego.
Jako ekipa Sentimenti już o tym, w jaki sposób skonstruowaliśmy i uczyliśmy algorytmy do automatycznej analizy emocji, zarówno na blogu, jak i w publikacji naukowej. Cześć naszej bazy słów (około 20%) zostanie opublikowana jako korpus towarzyszący publikacji opisującej szczegółowo zbieranie i analizę danych. Oznacza to, że ten zasób będzie dostępny dla naukowców z całego świata chcących badać emocje w języku polskim. Chcemy, żeby baza była interaktywna jak lista słów afektywnych NAWL, mająca swoją dedykowaną stronę.