
utworzone przez Sentimenti Team | lis 9, 2020 | Okiem badacza
Sztuczna inteligencja w dobie pandemii sprawdza się wyśmienicie. Tylko w tym roku w wyniku pandemii koronawirusa na całym świecie zostanie przetworzonych 59 zetabajtów danych.
Sztuczna inteligencja wspiera firmy w dobie pandemii
Rosnąca w lawinowym tempie ilość przesyłanych informacji wymusza błyskawiczną cyfryzację firm i administracji. Podstawą w tym procesie jest sztuczna inteligencja, która jednak wymaga stosowania odpowiedniej infrastruktury IT. Powszechnie stosowane dziś rozwiązania przestają wystarczać. Dlatego też coraz więcej przedsiębiorstw decyduje się na inwestycje. W co? W serwery zaprojektowane stricte z myślą o sztucznej inteligencji i analizie wielkich zbiorów danych. Już teraz są wykorzystywane także w walce z pandemią.
Sztuczna inteligencja to jedna z fundamentalnych technologii w procesie cyfrowej transformacji, dla której motorem są dane. Według dotychczasowych szacunków IDC globalna baza danych miała zwiększyć się z 45 w ubiegłym do 175 zetabajtów w 2025 roku, przy czym prawie 30 proc. z nich będzie musiało być przetwarzanych w czasie rzeczywistym. Nowsze prognozy pokazują jednak, że tylko w tym roku na całym świecie zostanie przetworzonych 59 ZB danych. Do tego wzrostu przyczyniła się pandemia COVID-19.
Wydatki na systemy oparte o SI będą przyspieszać
Zdaniem ekspertów wydatki firm na systemy SI będą znacząco przyspieszać. Organizacje coraz szerzej wdrażają je w ramach swojej cyfrowej transformacji, aby utrzymać konkurencyjność w realiach cyfrowej gospodarki. W ciągu najbliższych czterech lat globalne wydatki na SI mają się podwoić. Jak bardzo? Z obecnych 50,1 mld dol. do ponad 110 mld dol. w 2024 roku przy średniorocznej stopie wzrostu na poziomie ponad 20 proc. Rozwiązania SI wymagają jednak odpowiedniej architektury.
W tej chwili firmy potrzebujące bardzo dużych mocy obliczeniowych dość powszechnie korzystają z rozwiązań opartych na serwerach w architekturze x86 (stosowanej także w domowych komputerach).
Część organizacji zaczyna od nich odchodzić, bo przestają być wystarczające, a ich skalowanie wymaga np. fizycznej rozbudowy centrów danych, co pociąga też za sobą większe koszty zasilania czy chłodzenia.
Dla firm równie istotna jest niezawodność sprzętu. Wszelkie zakłócenia w realizacji operacji oznaczają straty finansowe. Ich wysokość może sięgnąć od kilku do nawet kilkuset tysięcy dolarów.

utworzone przez Agnieszka Czoska | lis 8, 2019 | Konferencje, Okiem badacza
Sentimenti to emocje. Pisaliśmy już o tym, jak poprawnie analizować emocje, gdy mamy sposób na ich automatyczny pomiar lub klasyfikację wzmianek. Dzisiaj opowiemy w jaki sposób zbieraliśmy dane pozwalające nam na stworzenie narzędzi Sentimenti. Czyli po raz kolejny piszemy jak dobrze coś zrobić – przeprowadzić badania nad emotywnym znaczeniem tekstów.
Tekst został napisany przy okazji wystąpienia na konferencji o uczeniu maszynowym GHOST Day. Tu można przejrzeć pokazywaną tam prezentację.
Sentimenti. Jakie emocje?
Żeby w ramach projektu Sentimenti wytrenować algorytmy uczenia maszynowego i automatycznie wskazywać emocje wyrażane w tekście, musieliśmy najpierw zapytać ludzi, jakie emocje czują. Tak proste pytanie musiało zostać rozłożone na kilka komponentów.
Po pierwsze – jakie emocje? Skąd mamy wiedzieć, ile ich jest, czym się różnią, jaka liczba kategorii będzie optymalna? Zajęli się tym specjaliści od emocji, ludzie z zespołu LOBI. W psychologii funkcjonuje kilka modeli emocji, od bardzo prostych po skomplikowane i wielowymiarowe. Zdecydowaliśmy się na dwa, które obecnie nazywamy po prostu modelami sentymentu i emocji.
Według modelu sentymentu zaproponowanego w artykule z 1977 roku przez Russella i Mehrabiana każdą emocję da się opisać na dwóch osiach: pozytywna-negatywna oraz wysokie-niskie pobudzenie. Jeśli chodzi o model emocji, jak wielokrotnie pisaliśmy, wygrał ten Plutchika. Oprócz względów naukowych przemawiały za nim praktyczne – część polskiej Słowosieci już została opisana emotywnie właśnie według niego. Dzięki zastosowaniu tego samego modelu (w poprawionym tłumaczeniu, nad którym też musieliśmy popracować) mogliśmy porównać wyniki naszych badań z eksperckimi anotacjami dostępnymi w tym zasobie. To jeden z naszych testów trafności wyników.
Jakie słowa?
Wiemy, jak anotować, ale co właściwie? Nasze pierwsze badanie miało skupić się na emotywnym znaczeniu słów. Zdecydowaliśmy, że w ramach testowania trafności wyników porównamy nasze z pochodzącymi ze Słowosieci, a dodatkowo bazą słów emotywnych NAWL (stworzoną dawniej przez naszych współpracowników z LOBI). Wobec tego jakaś część wyrazów musi pokrywać się z tymi zasobami.
Dążyliśmy do tworzenia listy 30 tys. słów lub znaczeń – w końcu mamy wiele wyrazów wieloznacznych, których wydźwięk emocjonalny także zmienia się w zależności od kontekstu. Na przykład depresja czyli obniżenie terenu to zupełnie coś innego niż zaburzenia nastroju. Uznaliśmy, że możemy wpisać na listę maksymalnie 3 znaczenia jednego słowa, a żeby wskazać uczestnikom badania, o które z nich chodzi, pokażemy każde w krótkiej frazie: depresja terenu, leczenie depresji.
Dzięki projektowi anotacji Słowosieci (przy jej rozwijaniu także pracują “nasi” ludzie) wiedzieliśmy, że około 27% słów języka polskiego niesie jakieś znaczenie emocjonalne. Z naszego punktu widzenia są one bardziej interesujące niż neutralne, więc miały pierwszeństwo. Poza tym kontrolowaliśmy naszą listę słów pod względem frekwencji słów (żeby mieć więcej tych częstych, ale także odpowiedni procent rzadkich).
Co z uczestnikami badania?
Jako zespół Sentimenti chcieliśmy móc powiedzieć coś o wydźwięku tekstów napisanych po polsku. Żeby naprawdę tak było, musieliśmy dowiedzieć się, jak rozumie je przeciętny, typowy użytkownik tego języka. Zgodnie z regułami naukowej sztuki musieliśmy przebadać reprezentatywna grupę Polaków – taką, której struktura odpowiada strukturze populacji pod względem wieku, wykształcenia i innych istotnych cech.
Takiego badania nie da się zrobić po prostu przez internet, w mediach społecznościowych, łapiąc ludzi na ulicy. Potrzebowaliśmy profesjonalistów, więc skorzystaliśmy z usług ogólnopolskiego panelu badawczego. Nasze zapytanie ofertowe wygrała Ariadna. Ta firma znalazła dla nas uczestników badania, ale my także kontrolowaliśmy przebieg badania. Musieliśmy zapewnić odpowiednią liczbę ocen wydźwięku każdego słowa (minimum 50 osób), nadawać uczestnikom badania identyfikatory (żeby móc zestawić ich odpowiedzi z danymi na temat wieku, miejsca zamieszkania i innych). W badaniu wzięło udział 20 tys. osób.
Jak pytać o wydźwięk słów?
Sentyment i pobudzenie emocjonalne zwykle opisuje się na skali. Z kolei modele emocji są raczej kategorialne – pytają, czy emocja jest, czy jej nie ma. Chyba, że mówimy o modelu Plutchika, który od razu zakłada, że natężenie emocji może się zmieniać: na przykład od irytacji przez złość po wściekłość. W naszym modelu chcieliśmy jeszcze dodać punkt zero, brak jakiejkolwiek emocji ze spektrum złości.
Po wielu analizach i pilotach stworzyliśmy autorskie narzędzie do anotacji emocji, dzięki któremu każde znaczenie słowa wpisanego we frazę można było ocenić na skalach będących operacjonalizacjami modeli sentymentu i emocji podstawowych. Uczestnicy badania wskazywali wydźwięk słowa dzięki interfejsowi pokazanemu poniżej. Wcześniej otrzymywali także dokładną, prosto napisaną instrukcję, do której mogli wrócić w każdym momencie badania.
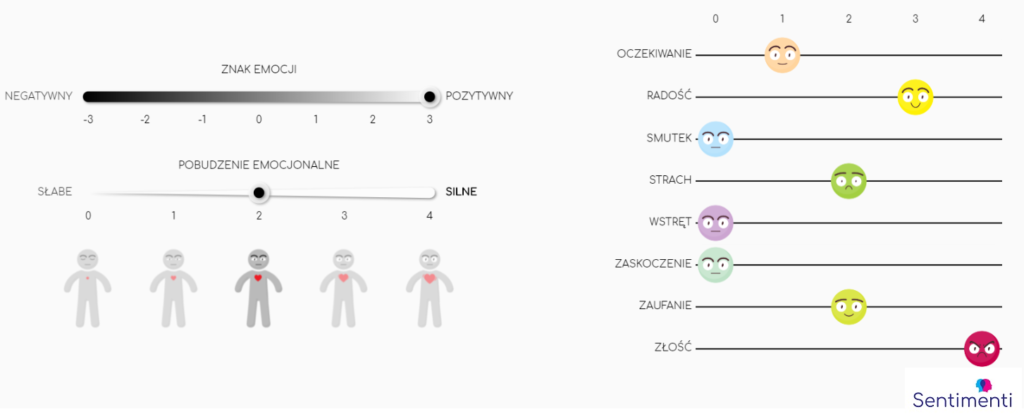
Bardzo ważnym etapem konstruowania badania było ustalenie, ile słów ma zobaczyć każdy uczestnik. Nie mogliśmy zajmować im zbyt dużo czasu chociażby dlatego, że zmęczeniu ludzie mniej uważnie czytają tekst i udzielają niestarannych odpowiedzi. Idealnym układem okazało się 150 słów (fraz) w trzech turach. Przerwy między turami mogły trwać nawet kilka dni. Dla nas liczył się czas spędzany nad każdą frazą (zbyt krótkie i zbyt długie musiały zostać odrzucone z wyników).
Dalej niż słowa
Nasze kolejne badanie miało dotyczyć wydźwięku tekstów. Językoznawcy nie od dzisiaj wiedzą, że od znaczenia słowa do znaczenia całego tekstu wiedzie kręta droga. Gramatyka i układ tekstu także wyrażają emocje.
Projekt zakładał, że przebadamy opinie – na przykład o hotelach i lekarzach. Zebranie opinii nie było trudne. Dodatkowo można było je podzielić na pozytywne i negatywne już na podstawie towarzyszących im gwiazdek lub ocen punktowych. Wyzwaniem było dobranie odpowiednich dziedzinowo tekstów neutralnych. Nasz korpus wzbogaciliśmy z krótsze formy, zdania i frazy, pochodzące między innymi z korpusu Paralingua lub naszych badań pilotażowych. Nieco później nasi koledzy pracujący także w zespole Słowosieci stworzyli korpus opinii (anotowany emotywnie już nie przez uczestników badań, tylko językoznawców).
Żeby wyniki były porównywalne z tymi dotyczącymi słów, przebadaliśmy wydźwięk tekstów z udziałem reprezentatywnej grupy osób na tych samych skalach, co słowa. To badanie objęło 2 tys. osób i 7 tys. tekstów i fraz. Każdy uczestnik przeczytał 50 tekstów, a każdy tekst oceniło co najmniej 25 osób.
Sentimenti to najpierw ludzie, potem AI
Obecnie nasze narzędzia do klasyfikacji tekstów pod względem emocji i sentymentu osiągają wysoką trafność dla każdej emocji. Najnowocześniejsze, najbardziej wymyślne sieci neuronowe czy inne algorytmy nie są w stanie tego dokonać bez dobrych danych. Mogliśmy nauczyć naszą sztuczną inteligencję emocji tylko dzięki temu, że zgromadziliśmy dobrze skonstruowaną bazę słów emotywnych i tekstów ocenionych przez reprezentatywną grupę użytkowników języka polskiego.
Jako ekipa Sentimenti już o tym, w jaki sposób skonstruowaliśmy i uczyliśmy algorytmy do automatycznej analizy emocji, zarówno na blogu, jak i w publikacji naukowej. Cześć naszej bazy słów (około 20%) zostanie opublikowana jako korpus towarzyszący publikacji opisującej szczegółowo zbieranie i analizę danych. Oznacza to, że ten zasób będzie dostępny dla naukowców z całego świata chcących badać emocje w języku polskim. Chcemy, żeby baza była interaktywna jak lista słów afektywnych NAWL, mająca swoją dedykowaną stronę.


utworzone przez Sentimenti Team | lip 25, 2019 | Kategoryzacja komentarzy
Sentimenti umożliwia w pełni automatyczną klasyfikację wzmianek i dłuższych tekstów pod kątem sentymentu i emocji. Odpowiada na pytania: czy ta wzmianka jest pozytywna, czy negatywne? Jakie emocje zostały w niej wyrażone? Dziś prezentujemy raport, w którym porównujemy wyniki naszej analizy z klasyfikacjami dwóch wiodących rozwiązań na rynku monitoringu polskojęzycznych mediów: Brand 24 i SentiOne.
W naszych dotychczasowych analizach wychodziliśmy od pomiaru emocji i sentymentu – ich wartość była wyrażana w procentach. Jednak klasyczne podejście do analizy sentymentu polega na klasyfikacji tekstów, zwłaszcza krótkich wzmianek z mediów społecznościowych. Nasze narzędzia także to potrafią.
W raporcie przyjrzeliśmy się wzmiankom publikowanym w czerwcu i lipcu na temat firmy CD Projekt i jej najnowszej produkcji “Cyberpunk 2077”. Wybraliśmy z nich niewielką próbkę do porównania z wynikami analizy sentymentu Brand 24 i SentiOne. Ograniczyliśmy się do kilkudziesięciu wzmianek, aby każda Czytelniczka i każdy Czytelnik mógł sam je ocenić . Podstawą porównania nie są dla nas tylko wyniki samych narzędzi do monitoringu mediów. Zebraliśmy trzech ekspertów od emocji – po prostu trzy osoby. Tak, jak ak podczas konstrukcji naszych narzędzi zaczynamy od tego, co myślą i czują ludzie. Które z porównywanych rozwiązań jest “najbardziej ludzkie”? My już wiemy.
Na podstawie przeanalizowanych 31 wzmianek możemy stwierdzić, że najlepiej wypada algorytm BiLSTM Sentimenti, następnie narzędzia B24 i SentiOne. Warto dodać zastrzeżenie – ten wynik jest ważny tylko dla tej małej próbki, dlatego wkrótce zaprezentujemy wyniki kolejnych porównań, na większych zbiorach danych.
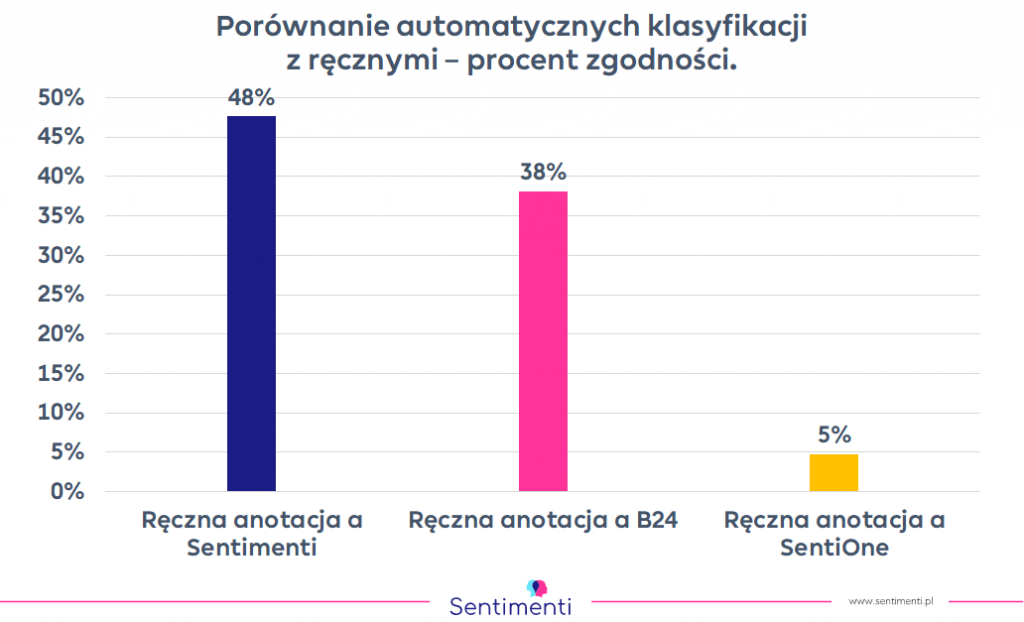
Jeśli chcesz wiedzieć więcej, przeczytaj nasz raport, w którym znajdziesz:
- metodologię badania
- listę wzmianek wraz z ocenami
- analizę emocji wyrażonych we wzmiankach
Raport “Analiza sentymentu w monitoringu mediów” można obejrzeć tutaj.


utworzone przez Sentimenti Team | maj 30, 2019 | Kategoryzacja komentarzy, Okiem badacza
Sposób w jaki ludzie przekazują sobie emocje przez lata nie poddawał się algorytmizacji, czyli opisowi zrozumiałemu dla komputerów. Wydawało się, że maszyny będą sobie radzić doskonale z liczeniem, zapamiętywaniem, może nawet z rezerwowaniem stolików w restauracji czy biletów lotniczych – ale sfera “serca” pozostanie domeną czysto ludzką.
Tak rzeczywiście się działo, kiedy próbowaliśmy wyjaśniać komputerom “krok po kroku” jak rozumieć emocje. Algorytmy regułowe stawały się bezradne przy każdej wieloznaczności czy zmianie struktury wypowiedzi.
Rewolucyjne podejście do analizy emocji. Rola maszyny
Od kilku lat do analizy tekstu wkraczają algorytmy uczenia maszynowego (ang. machine learning), w tym ich najnowsza wersja – sieci neuronowe (ang. neural networks), które uczą się “tak jak małe dziecko”, czyli przez oglądanie przykładów. To zupełnie zmieniło sytuację – teraz, jeśli mamy dobre dane i dobry algorytm, możemy nauczyć komputer prawie wszystkiego.
Zespół SENTIMENTI przygotował publikację naukową dotyczącą tego właśnie tematu, która została zaprezentowana podczas międzynarodowej konferencji Language Technology Conference. Publikacji przewodniczy dr Jan Kocoń z Politechniki Wrocławskiej, a jej tytuł to “Recognition of emotions, valence and arousal in large-scale multi-domain text reviews”. Pełna treść pracy będzie wkrótce dostępna w zbiorze pokonferencyjnym, natomiast tutaj prezentujemy najważniejsze wnioski z naszych badań.

Dr Jan Kocoń prezentuje wyniki badań SENTIMENTI na LTC 2019
Uczenie maszynowe w Sentimenti
Zacznijmy od podstawowych kroków uczenia maszynowego dla analizy emocji w tekście:
- Anotacja – przygotowanie zbioru uczącego i testowego (ang. train and test set).
- Wybór algorytmu uczącego (np. SVM, BiLSTM i in.)
- Dobór zbioru cech (ręczny lub automatyczny)
- Trening i dostrajanie sieci neuronowej.
- Testowanie efektywności otrzymanego modelu (miara F-score lub inna).
Co to znaczy, że sieci neuronowe “działają jak ludzki mózg”? Tak jak niemowlę, sieć zaczyna z pewną gotową do uczenia się strukturą, ale bez żadnej wiedzy. Musi zobaczyć wiele, wiele przykładów, aby “zrozumieć” jak działają różne zjawiska (skala liczebności tych przykładów zaczyna się od dziesiątek lub setek tysięcy). Nauczona sieć potrafi samodzielnie analizować nowe, wcześniej nie widziane przykłady, korzystając z rozpoznanych wcześniej cech.

Jakich informacji potrzebuje sieć neuronowa, aby nauczyć się rozpoznawać emocje? Tak jak dziecko, potrzebuje informacji zwrotnej o tym co jest, a co nie jest prawidłowe. Ten rodzaj uczenia maszynowego nazywamy uczeniem nadzorowanym (ang. supervised machine learning). Dla danych językowych, sieć potrzebuje szeregu anotacji, czyli przykładów o postaci np.:
- przepiękny = szczęście 0,8
- znalezisko = zaskoczenie 0,7
- nieuczciwość = złość 0,4
Najważniejsze są nie maszyny, a dane
Jak jednak zdobyć dziesiątki tysięcy takich przykładów potrzebnych do nauczenia sieci neuronowych? I co zrobić ze słowami, które będą wzbudzały różne emocje u różnych osób? Jeśli słowo “kolejka górska” wzbudza we mnie radość, a w tobie strach, to czyją wersję powinniśmy przekazać naszemu “neuronowemu dziecku”?
Problem dobrej jakości danych do uczenia maszynowego był bolączką wielu poprzednich projektów uczenia maszynowego, dlatego w Sentimenti zaangażowaliśmy zespół doświadczonych psychologów z LOBI PAN i przeprowadziliśmy największe w Polsce badania emocji w słowach. Zapytaliśmy ponad 20 tys. osób o ponad 30tys. słów i 7 tys. tekstów, z których każdy był oceniony ok. 25 -50 razy (więcej szczegółów na naszym blogu link). Mamy dzięki temu najbardziej reprezentatywną informację o 8 emocjach, jakie poszczególne słowa i teksty wzbudzają u Polek i Polaków.
Lepsza automatyczna analiza emocji w tekście
Stworzenie dobrej bazy danych pozwoliło nam przejść do kolejnego kroku, czyli wyboru algorytmu uczenia maszynowego, który najlepiej podoła zadaniu “odgadywania” emocji w tekście. Przetestowaliśmy następujące rozwiązania, które “nakarmiliśmy” naszymi danymi:
- word embeddings i word2vec (czyli metodę przekształcania słów i tekstów na postać matematyczną);
- fastText (jako podstawową metodę, punkt odniesienia);
- BiLSTM (ang. bidirectional long-short-term memory neural network, czyli dwukierunkowe sieci oparte na krótko- i długoterminowej pamięci);
Nasze algorytmy rozpoznawały sentyment trafnie w 89%, natomiast emocje w ok. 80-85% (dla wybranej grupy tekstów). Szczegółowe miary i informacje o dziedzinach, a także wiele pomiętych tutaj szczegółów badania, można znaleźć w naszej publikacji na stronie LTC.
Dzięki temu badaniu mamy dostępne modele, które rozpoznają emocje szybciej niż człowiek – są w stanie przetworzyć w ciągu kilku minut miliony tekstów.
W dziale B+R Sentimenti ciągle pracujemy nad nowymi rozwiązaniami, dlatego już teraz eksperymentujemy z technologiami, które zrewolucjonizowały świat NLP (ang. Natural Language Processing) w 2018 roku, takimi jak BERT i ELMo, ciągle rozwijamy też własne modele i rozwiązania dla lepszego zrozumienia emocji w języku.
Współpraca przy tej notce: dr Barbara Konat, kierowniczka badawcza w SENTIMENTI

utworzone przez Agnieszka Czoska | lis 29, 2018 | Okiem badacza
Dr Jan Kocoń jest inżynierem języka naturalnego – to on odpowiada za uczenie maszynowe zamknięte w SentiToolu, naszym narzędziu do analizy emocji w tekście. Koordynuje prace zespołu językoznawczego, integruje poszczególne elementy narzędzia, ściśle współpracuje z zespołem informatycznym.
Kiedy masz komuś pierwszy raz opowiedzieć o Sentimenti i naszych narzędziach, co mówisz najpierw?
Sentimenti jest projektem, w którym zajmujemy się analizą emocji w tekście. W odróżnieniu od rozwiązań konkurencji, w których rozpoznaje się wyłącznie wydźwięk tekstu (pozytywny, neutralny, negatywny), nasze narzędzia są w stanie zrozumieć tekst, przypisać wyrazom w tekście konkretne znaczenia oraz emocje, jakie ludzie odczuwają w związku z tymi znaczeniami. Emocje te stanowią z kolei bazę wiedzy dla mechanizmu uczenia maszynowego, który dokonuje automatycznego rozpoznawania emocji na poziomie zdań oraz całego tekstu.
Co to znaczy, że analizujemy emocje w tekście?
W badaniach prowadzonych w projekcie zaadaptowaliśmy model Plutchika, obejmujący osiem emocji podstawowych: radość, smutek, zaufanie, wstręt, oczekiwanie, strach, zaskoczenie oraz złość. Jesteśmy w stanie oszacować, w jakim stopniu te emocje są wyrażone w tekście.
Skąd wiemy, jakie emocje ludzie czują?
Baza wiedzy, która jest pomocą dla naszego projektu, obejmuje ponad 30000 znaczeń słów, dla których 20000 unikatowych respondentów przypisuje oceny dotyczące wydźwięku oraz emocji. Mówimy tu o “znaczeniach”, a nie “słowach”, bo wyrazy są wieloznaczne, na przykład “ciemny” znaczy co innego w “ciemny błękit” lub “ciemny lud” i tylko w tym drugim przypadku niesie emocje. Każde znaczenie docelowo otrzyma 50 ocen od różnych osób. Dzięki temu wiemy, jakie odczucia wywołują określone znaczenia w tekście. Jednak emocja tekstu nie jest prostą sumą emocji przypisanych do znaczeń występujących w tym tekście…
Co jeszcze sprawia, że narzędzia do analizy emocji w tekście działają?
Z pomocą przychodzą nam dwie rzeczy. Pierwszą z nich jest nasza gigantyczna baza opinii z przyporządkowanym wydźwiękiem, które pochodzą z różnych dziedzin: podróże, medycyna, produkty i wiele innych. Mamy ponad 10 milionów takich tekstów, co stanowi doskonałe źródło informacji o ogólnym odczuciu twórcy tekstu. Jednak aby stwierdzić, jakie emocje dany tekst wywołuje u czytelnika, prowadzimy także własne badania, analogiczne od badań prowadzonych na pojedynczych znaczeniach. Przedmiotem tych badań są tym razem teksty. Osoby ankietowane przypisują im emocje podstawowe, dokładnie tak samo jak znaczeniom słów. Drugi filar naszego narzędzia to kombinacja wielu metod uczenia maszynowego. Eksperci od przetwarzania języka naturalnego dostarczają nam narzędzi do analizy tekstu na poziomie składniowym oraz semantycznym, dodatkowo tworzą reguły analizy znaczeń w kontekście jak: negacja, przypuszczenie, osłabienie lub wzmocnienie wydźwięku itp. Jest to dodatkowa pomoc dla metod automatycznych, na przykład głębokich sieci neuronowych, za pomocą których odbywa się właściwe wnioskowanie na temat emocji w tekście.
Do czego może się według ciebie przydać automatyczna analiz emocji?
Docelowo widzę wiele zastosowań dla naszych narzędzi. Pierwszy obszar obejmuje rynek reklam wyświetlanych w kontekście artykułów internetowych i dopasowywanie ich do emocji, jakie tekst publikacji wzbudza u czytelników. Przykładowo w smutnym tekście mogłaby pojawić się reklama towarzystwa ubezpieczeniowego, a w radosnym – reklama wycieczki. Kolejnym obszarem jest monitoring marki, czyli analizowanie jak klienci firm piszą w Internecie o danej firmie, jej produktach, jakie emocje im przy tym towarzyszą. Kolejne interesujące obszary to sortowanie skarg mailowych od klientów względem emocji w nich zawartych, detekcja konfliktów rodzących się w korespondencji pracowników, wykrywanie kryzysów w mediach społecznościowych, a nawet możliwość diagnozowania chorób psychicznych – potencjał jest naprawdę ogromny.
Co jeszcze planujesz zrobić w Sentimenti?
Póki co, jest gotowy prototyp z prostą analizą tekstu na poziomie znaczeń oraz z analizą wydźwięku z wykorzystaniem naszych wielkich zasobów opinii. Obecnie we Wrocławskim zespole Sentimenti zarządzam budową mechanizmu uczenia maszynowego, w którym możliwe będzie zagregowanie zarówno informacji z bazy wiedzy dotyczącej znaczeń, jak i informacji pochodzących z potoku przetwarzania języka naturalnego. Wciąż spływają nam nowe dane o odczuciach osób czytających teksty, stanowiące nasz zbiór uczący. Im więcej danych, tym lepsza jakość narzędzia.